Email filtering
Type of Activity
This is a multi-week project that is well suited to having pieces given
as homework assignments.
Outline of Scientific Context
This project is about classifying email messages as spam or
ham (regular email). We work from the SpamAssassin corpus of
about 9000 hand-classified messages. (These are somewhat dated now,
but the computations are still relevant.)
These messages are organized into a set of directories where each
email message is in its own file and the directory/file name indicates
whether the message is spam or ham.
There are two sets of data - training data that are used to create
predictors for spam and test data for evaluating the effectiveness
of the predictor.
Computational Topics Covered
I/O, including file system tools to find files;
data structures, where the data are extracted from text that
is both structured (email header) and unstructured (email body) and
stored in a list with a complex format;
text manipulation and regular expressions;
visualization, mostly simple plots for EDA;
writing functions, e.g. functions to derive variables from the unstructured text;
computational aspects of Naive Bayes;
resampling, cross-validation.
Learning Objectives
- learn about a common technology: email, including the anatomy of an email message
- understand that the typical GUI for file manipulation is not adequate
when handling large volumes of data
- experience with regular expressions and text manipulation
- facility with subsetting observations using compound conditional statements.
- exposure to approaches to debugging, e.g. using small test data sets and visualization
- ability to work with complex data structures
- write efficient code (e.g. for computining the Naive Bayes classifier);
Level/Target Student
The target audience is an advanced undergraduate/first year graduate student.
The undergraduate student may work on only one of the branches of analysis
(see below). The graduate student may do both branches, or delve deeper
into the computational aspects of the Naive Bayes classifier.
How to integrate into a class
This is a multi-week project.
Some tasks in this project can be used as stand-alone homework assignments.
In this case, the project need not be assigned, or it could be covered
by the instructor. The derivation of data from the text makes a good homework
assignment where groups of students can write functions to derive different
variables from the text and the derived data can be subsequently shared
with the entire class for the subsequent stages of the project.
On the other hand, the students cold be provided with data that is already
"processed" if the focus is on the derivation of the classifier.
Breakdown of Computational Tasks
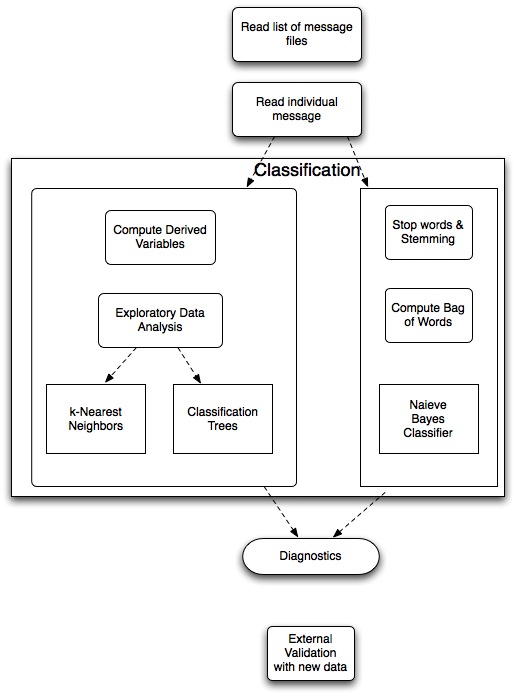
Solutions
-
- [File listing] The students find the collection of email messages
in 5 directories and have to use file system tools to
find these files and which are spam and which are ham
based on the directory & file names.
-
-
- [Text Manipulation] The student writes a function to parse an email message
into header, body and attachments.
This involves readLines() and
string manipulation. One can use read.dcf() (with limitations)
to read the header and its
name: value pairs.
However, strsplit() is the general way to do this
along with handling continuation lines which can be done
with grep() or substring(, 1, 1) to see if the first character is
white space.
-
-
- [Regular Expressions & Text Manipulation] Next we create ~ 30 derived variables from each message.
This involves a lot of text manipulation.
Some involve regular expressions, while some can be done
with nchar() and simple string operations.
There may be issues wih character encoding within some messages.
-
-
- [EDA] We now have ~ 30 + 1 (SPAM/HAM) variables and we look
at numerical summaries (via table()) and graphical displays
to try to see what variables are useful in classifying the
messages as being SPAM or HAM.
This also involves subsetting and combining conditions
such as
numCapitalsInSubject < 10 & inReplyTo & hourSent %in% 2:4
Mosaicplots arise naturally in this context.
-
-
- [Classification]
We use one of three different approaches, each with different
pedagogical foci w.r.t. computational techniques.
All involve basic aspects of efficiency.
- k Nearest Neighbors
- Computing distance matrix
- Cross-validation
- Determining the k nearest neighbors
- Recognizing that k + 1 nearest neighbors include
the k nearest neighbors.
- Classification Trees
-
The students uses the rpart package and the rpart()
function.
This takes care of many of the computations for the
student.
The do see the formula language.
They should understand cross-validation that is done
within rpart().
- Efficiency and Type I errors - montone property of type I error function - discreteness of the empirical
function
-
- [Validation]
- Build model on one dataset, validate on a second dataset - post mortem analysis
- Explore the confusion matrix and the mis-classified messages to
see if we can understand what messages were difficult? what
were easy?
- Validate the classifier on an entirely separate dataset and
understand why it does well? worse? than the test/training set approach?
Cautionary Notes
The derivation of data from the text can be quite time consuming.
We often assign different variables to derive to different groups of students.
This is done as a homework assignment, and then when the class is ready to embark
on the next step of the project, all derived variables are made available to
all of the students. In this case, we provide the derived data, in case students
have made mistakes in their derivations.
Students tend to perform univariate analyses when exploring the data and
checking to see how well their classifier works. We encourage them to take
a multivariate approach to the problem.
We found that students needed assistance recognizing that to test code,
they might want to try it on a small subset of the data, rather than the
entire data.
Ways to Extend the Topic
-
- Try boosting to improve the performance of the classifier.
-
Other Directions
-
- Naieve Bayes
-
- Preparing the data for Naieve Bayes - bag of words, word frequencies, computing message probabilities
- Nuisance parameter needed for the model - cross validation -
stratified or balanced sampling - one bag of words for all validation
sets
-
- One could use Perl modules to read the mail messages. This
could be done using RSPerl to avoid having to write the code to
parse the messages, especially some of the complex material.
-
-
- One could deploy the classifier we develop in a procmail setup.
-
Grading Suggestions
If the assignment is broken into separate assignments, then the instructor may
want to consider supplying the results of one assignment,
e.g. data or functions, that are needed for a subsequent task.
Duncan Temple Lang
<duncan@wald.ucdavis.edu>
Last modified: Wed Jul 22 08:35:35 PDT 2009