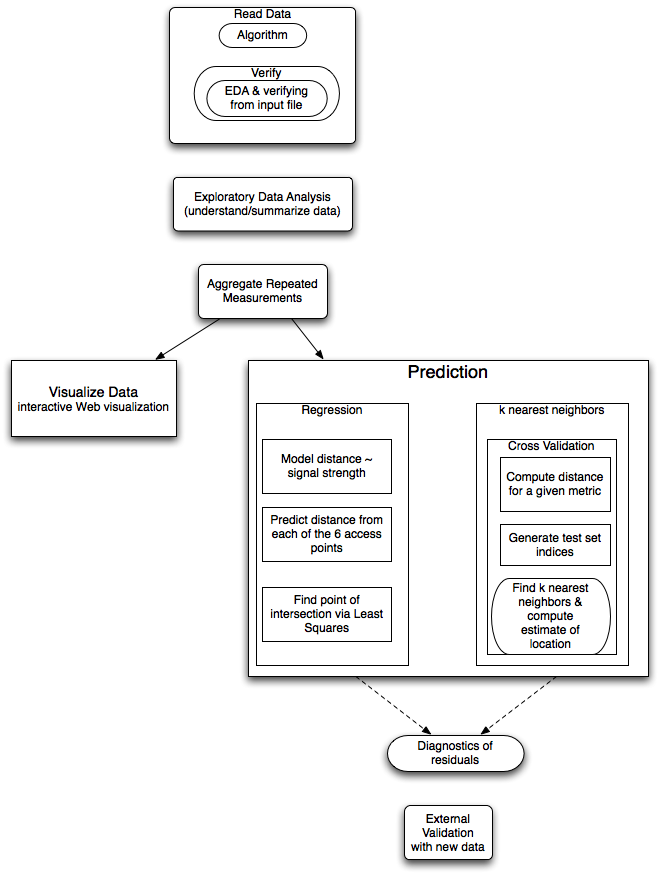
This is a multi-week project where pieces of is could be broken off and presented as homework assignments.
This project involves trying to predict the location of a wireless device based on the signal strength received at 6 different fixed access points (routers) within a building. It is of interest as GPS does not work well within buildings and the hope is to get more accurate predictions. The experiment associated with this particular data set also includes orientation, i.e. the direction the person holding the device is facing as this is expected to have a significant impact on signal strength when the person is between the device and an access point.
The data come from researchers at the university of Mannheim, Germany and we obtained via CRAWDAD. The project-specific site is http://crawdad.cs.dartmouth.edu/meta.php?name=mannheim/compass.
There are two sets of data - training (offline) data and test (online) data. There are approximately 1 million records in the offline data. There are many repeated measurements and significant complexity to visualizing the volume of data wrt the small number of factors. This clearly has a spatial component.
We (Deb and I) worked on this in 2007 (?). There is now a new data set and a different building plan.
[;=] when using
strsplit();
None for the k-nearest neighbor approach. This can be taught as part of the activity.
If one uses the regression approaach, then of course the students should know enough about regression to be able to fit a model and understand what it means, to be able to use transformed variables and do diagnostics.
This is a multi-week project. The data input can be covered separately, early on, where the focus would be on getting the data into a format for analysis. One can also give the students the data and have them explore it and produce interesting graphical displays and summaries when discussing graphics early in the course (after they have seen data frames and subsetting).
The target a udience is an advanced undergraduate/first year graduate student. The graduate student audience may delve deeper into the model fitting aspects of the project.
t=1139692477303;id=00:02:2D:21:0F:33;pos=0.0,0.05,0.0;degree=130.5;00:14:bf:b1:97:8a=-43,2437000000,3;00:0f:a3:39:e1:c0=-52,2462000000,3;00:14:bf:3b:c7:c6=-62,2432000000,3;00:14:bf:b1:97:81=-58,2422000000,3;00:14:bf:b1:97:8d=-62,2442000000,3;00:14:bf:b1:97:90=-57,2427000000,3;00:0f:a3:39:e0:4b=-79,2462000000,3;00:0f:a3:39:e2:10=-88,2437000000,3;00:0f:a3:39:dd:cd=-64,2412000000,3;02:64:fb:68:52:e6=-87,2447000000,1;02:00:42:55:31:00=-85,2457000000,1 t=1139692477555;id=00:02:2D:21:0F:33;pos=0.0,0.05,0.0;degree=130.5;00:14:bf:b1:97:8a=-43,2437000000,3;00:14:bf:b1:97:8a=-43,2437000000,3;00:0f:a3:39:e1:c0=-52,2462000000,3;00:14:bf:b1:97:90=-57,2427000000,3;00:14:bf:b1:97:8d=-64,2442000000,3;00:0f:a3:39:e0:4b=-77,2462000000,3;00:0f:a3:39:dd:cd=-62,2412000000,3;02:00:42:55:31:00=-85,2457000000,1;02:64:fb:68:52:e6=-88,2447000000,1So we have to get the time stamp, then the MAC of the hand-held device, then the position and orientiation. Then we have a ragged array of mac=triple.
This is one of those formats that requires some thought to identify the pattern that makes the code simple to read into an R data structure. One also has to think carefully about the right data format.
The auxiliary data giving the locations of the access points can be given as a CSV file or an RDA file.
There are all sorts of issues with standard errors of the different estimates and weighting the predictions, i.e. variance of the distance estimates probably increas with distance (i.e. less accurate the further away we are). We could use tehse in a weighted least squares to solve the "point of intersection".
There can be confusion computing distances in the space of signal strength and distance in the physcial space of the building. The k-nearest neighbors works on the signal strengths and distance between two observations is the sum over access points of the squared differences between the signal strengths to the same access point.