Smoothers
1 Smoothers
In many of the graphs we've looked at, we added a straight line representing the
best linear regression line that went through the data we were plotting. Such lines can
be very helpful when there are lots of points, or when outliers might detract from our
seeing a relationship among the points.
But plotting the best linear regression line has some limitations. For one thing,
the regression has to fit all the data, so finding a good regression fit is often a
compromise between being true to the data in any given range, and trying to come up with
a single line that does reasonably well throughout the entire range. For some data, this
may be appropriate. For example, if we know that two variables really follow a linear
relationship, then we'd have to assume that deviations from that relationship are just
noise, and the best straight line would be a meaningful way to display their relationship
on a graph. However, situations like that are not that common.
To come up with a way of visualizing relationships between two variables without
resorting to a regression lines, statisticians and mathematicians have developed
techniques for smoothing curves. Essentially this means drawing lines through the points
based only on other points from the surrounding neighborhood, not from the entire set of
points.
There are many different types of smoothers available, and most of them offer an
option that controls how much smoothing they will do as well as options to control the
basic methods that they use, so it's usually possible to find
a smoother that will work well for a particular set of data.
2 Kernel Smoothers
Kernel smoothers work by forming a weighted average of all the y-values corresponding
to points whose x-values are close to the x-value of a point being plotted. The
function that defines the weights is known as a kernel, and the number of points involved
in the weighted average is based on a parameter known as the bandwidth. The default
kernel is a box function; in other words, it simply averages together y-values which are
within the specified bandwidth of a given x-value, and uses that average as the y-value
for the x-value in question. With a very tiny bandwidth, this corresponds to a
"connect-the-dots" type of drawing. With a very large bandwidth, it will basically
estimate every y-value as the mean of all the y-values. However, even when the bandwidth
is carefully chosen, using the box kernel rarely will result in a truly smooth graph.
For example, consider a plot of OD.Ratio versus Proanthocyanins from
the wine data set that we've used in previous examples. The following code
produces a plot of the variables, and superimposes a line representing a box kernel
smooth with the default bandwidth:
> plot(wine$Proanthocyanins,wine$OD.Ratio)
> lines(ksmooth(wine$Proanthocyanins,wine$OD.Ratio))
Here's the graph:
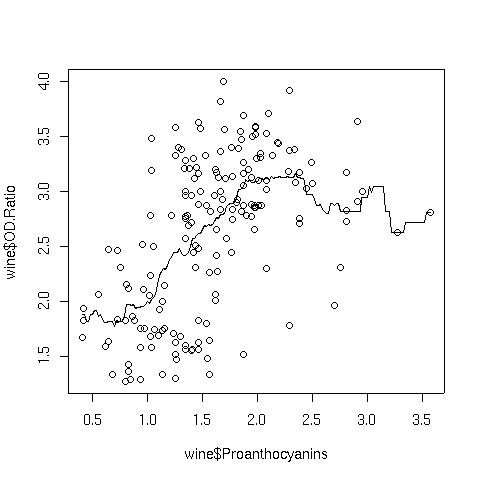 Notice how choppy the line is, especially where there isn't much data. That's because
the box kernel is too extreme - it either adds in a point or not. So using the box
kernel is like stacking up a bunch of square boxes around each point, and we don't really
get a smooth result.
More commonly, kernels will have a maximum at distances that are very small, and will
decrease gradually as the (absolute value) of the distance from the center of the
kernel increases. This means that nearby points will have lots of influence on the
weighted estimate that will be plotted, but as we move away from a particular point,
the neighboring points will have less and less influence. We can modify how many
points are considered through the bandwidth - including more points tends to give
smoother curves that don't respond as well to local variation, while decreasing the
bandwidth tends to make the curve look "choppier". One of the most common kernels
used in smoothing is the Gaussian or normal kernel. This kernel is the familiar
"bell curve" - largest in the middle (corresponding in this cases to distances of
zero from a particular point), and gradually decreasing over it's supported range.
The width of that range is determined by the bandwith when using a kernel smoother.
Here's the Proanthocyanins vs. OD.Ratio plot, smoothed with a
normal kernel using the default bandwidth:
Notice how choppy the line is, especially where there isn't much data. That's because
the box kernel is too extreme - it either adds in a point or not. So using the box
kernel is like stacking up a bunch of square boxes around each point, and we don't really
get a smooth result.
More commonly, kernels will have a maximum at distances that are very small, and will
decrease gradually as the (absolute value) of the distance from the center of the
kernel increases. This means that nearby points will have lots of influence on the
weighted estimate that will be plotted, but as we move away from a particular point,
the neighboring points will have less and less influence. We can modify how many
points are considered through the bandwidth - including more points tends to give
smoother curves that don't respond as well to local variation, while decreasing the
bandwidth tends to make the curve look "choppier". One of the most common kernels
used in smoothing is the Gaussian or normal kernel. This kernel is the familiar
"bell curve" - largest in the middle (corresponding in this cases to distances of
zero from a particular point), and gradually decreasing over it's supported range.
The width of that range is determined by the bandwith when using a kernel smoother.
Here's the Proanthocyanins vs. OD.Ratio plot, smoothed with a
normal kernel using the default bandwidth:
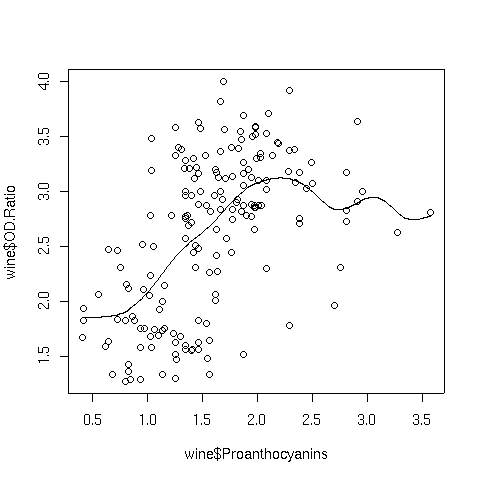 Notice the change in the line when switching to the normal kernel; the line
is now smooth, and we can see that a linear relationship that holds up until around
a Proanthocyanin concentration of about 2.
Notice the change in the line when switching to the normal kernel; the line
is now smooth, and we can see that a linear relationship that holds up until around
a Proanthocyanin concentration of about 2.
3 Locally Weighted Regression Smoothers
Another approach that is often used to smooth curves is locally weighted regression.
Instead of taking a weighted average of y-values near the x-values we want to plot,
the nearby points are used in a (usually quadratic) weighted regression, and predicted
values from these local regressions are used as the y-values that are plotted.
The lowess function in R implements this technique by using the reciprocal
of the residuals of successive fits as the weights, downgrading those points that
don't contribute to a smooth fit. In the lowess function, the argument
f= specifies the fraction of the data to be used in the local regressions.
Specifying a larger value results in a smoother curve.
To illustrate, consider a plot of literacy versus phys, the number
of physicians per 100000 people, from the world data set that we've used in
previous examples. The following code produces a plot of the data with a lowess
smoothed curve superimposed:
> plot(world$literacy,world$phys)
> lines(lowess(world$literacy,world$phys))
The graph appears below:
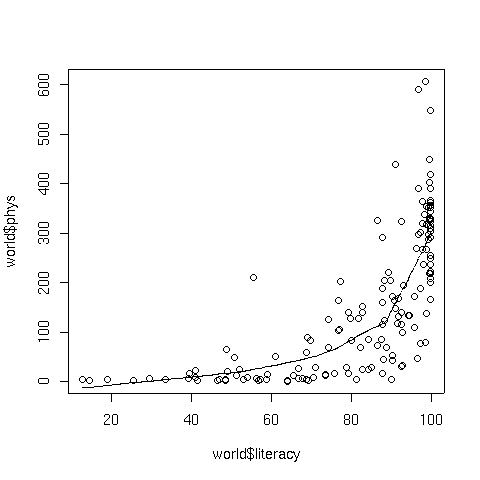
4 Spline Smoothers
Another type of smoothing is known as spline smoothing, named after a tool formerly
used by draftsmen. A spline is a flexible piece of metal (usually lead) which could
be used as a guide for drawing smooth curves. A set of points (known as knots) would
be selected, and the spline would be held down at a particular x,y point, then bent to
go through the next point, and so on. Due to the flexibility of the metal, this
process would result in a smooth curve through the points.
Mathematically, the process can be reproduced by choosing the knot points and using
(usually cubic) regression to estimate points in between the knots, and using calculus
to make sure that the curve is smooth whenever the individual regression lines are
joined together.
The smooth.spline function in R performs these operations.
The degree of smoothness is controlled by an argument called spar=, which
usually ranges between 0 and 1.
To illustrate, consider a data set consisting of the wheat production of the United
States from 1910 to 2004. The data set can be found at
http://www.stat.berkeley.edu/~spector/s133/data/wheat.txt.
The following lines will produce a plot of the data, and superimpose a spline smooth.
> wheat = read.table('http://springer/data/wheat.txt',header=TRUE)
> plot(wheat$year,wheat$production)
> lines(smooth.spline(wheat$year,wheat$production))
Here's the result:
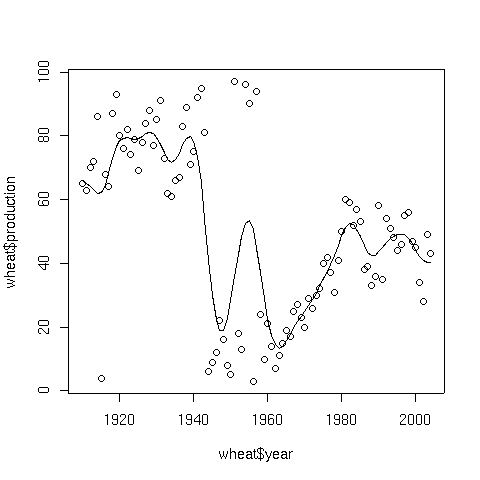
5 Supersmoother
While most smoothers require specification of a bandwidth, fraction of data, or level
of smoothing, supersmoother is different in that it figures these things out for
itself. Thus, it's an excellent choice for situations where smoothing needs to be done
without any user intervention. Supersmoother works by performing lots of simple
local regression smooths, and, at each x-value it uses those smooths to decide the best
y-value to use. In R, supersmoother is made available through the supsmu
function.
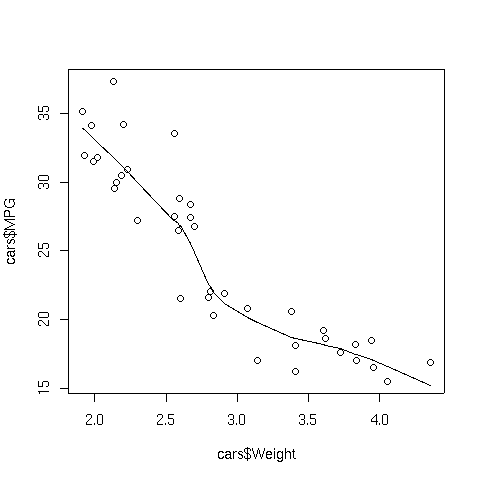
To illustrate, consider the car data which we used earlier when we were studying
cluster analysis. The following lines produce a plot of weight
versus MPG, and superimposes a supersmoother line.
> plot(cars$Weight,cars$MPG)
> lines(supsmu(cars$Weight,cars$MPG))
The plot appears below:
6 Smoothers with Lattice Plots
When working with lattice graphics, we've already seen the use of panel.lmline,
which displays the best regression line in each panel of a lattice plot. A similar
function, panel.loess, is available to superimpose a locally weighted regression
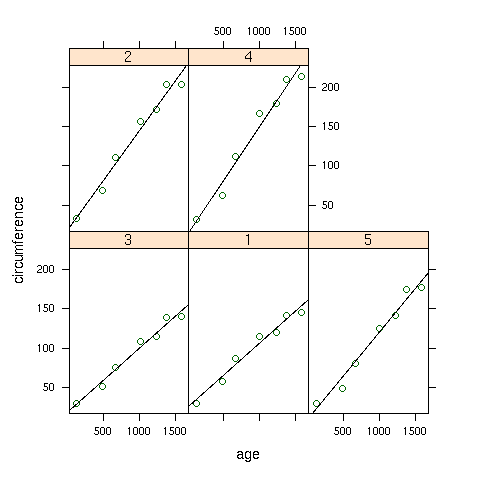
smoother in each panel of a plot. As a simple illustration, consider the built-in
Orange data set, which has information about the age and circumference of
several orange trees. First, let's look at a plot with the best regression line
smoother superimposed on the plot of age versus circumference for
each Tree:
> library(lattice)
> xyplot(circumference~age|Tree,data=Orange,
+ panel=function(x,y,...){panel.xyplot(x,y,...);panel.lmline(x,y,...)})
Here's the plot:
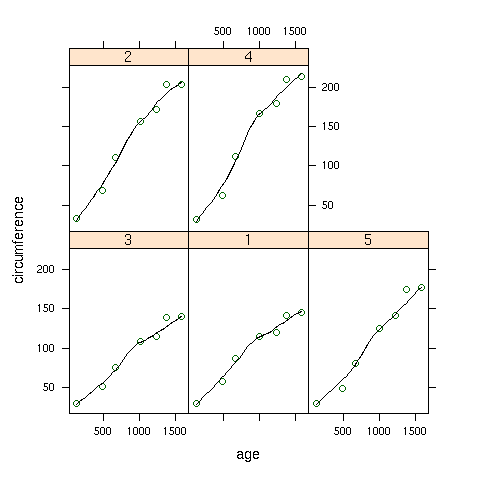
 To create the same plot, but using the panel.loess function, we can use
the following:
To create the same plot, but using the panel.loess function, we can use
the following:
> xyplot(circumference~age|Tree,data=Orange,
+ panel=function(x,y,...){panel.xyplot(x,y,...);panel.loess(x,y,...)})
Here's how the plot looks:
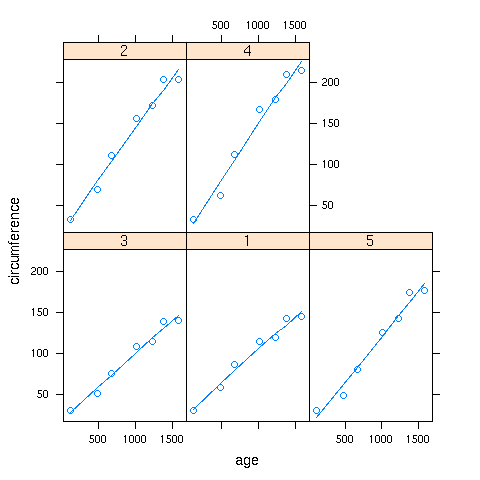
 If a panel. function doesn't exist for a smoother you'd like to use,
you can use the panel.lines function to plot it directly:
If a panel. function doesn't exist for a smoother you'd like to use,
you can use the panel.lines function to plot it directly:
> xyplot(circumference~age|Tree,data=Orange,
+ panel=function(x,y,...){panel.xyplot(x,y,...);z=supsmu(x,y);panel.lines(z$x,z$y,...)})
In this case supersmoother came closer to a straight line than lowess.
File translated from
TEX
by
TTH,
version 3.67.
On 30 Nov 2007, 08:46.