+Type of Activity
This is more of a keyword or brief indication as to whether the activity as contained in the solutions is
a multi-week involved project with many parts,
a homework assignment that might take a week to do and may be a single problem or several separate questions
a single question that might be one of several on a week-long homework,
an in-class exercise.
An activity may fit into many categories or be expandable/contractable. You can address these below.
+Level/Target Student
Identify the level of the student for whom this writeup is primarily intended. Again, the activity might be readily adaptable to different students, but we are interested here in this particular writeup of the solutions. You can address how different audiences can be accommodated below.
+Outline of Scientific Context
Describe the data and the question(s) and why this activity is of interest. Describe why this is interesting to a statistician or how she might be involved.
There may be separate versions for the students and for the instructor.
+Computational Topics Covered
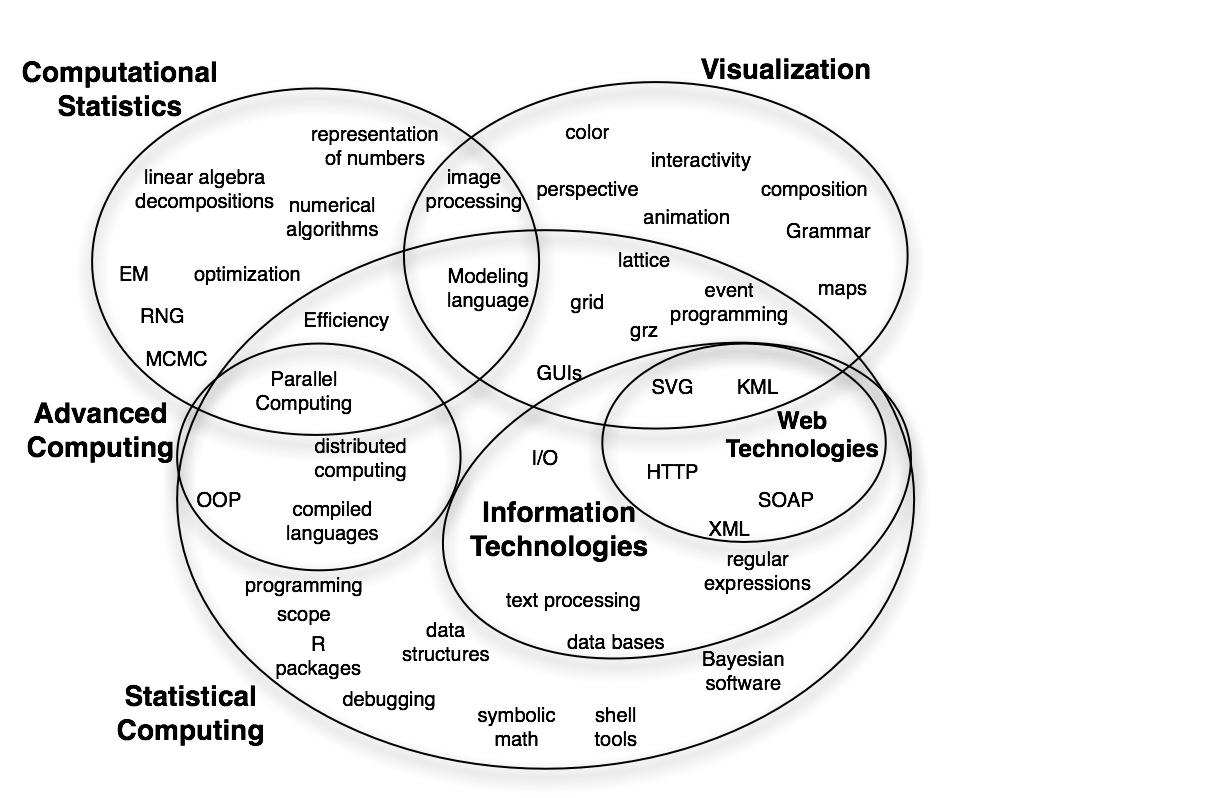
The intent here is to identify the high-level computational topics/themes rather than individual functions. (We hope that with suitable markup in the solutions, we will be able to programmatically identify the functions and packages from the solutions.) Examples of these topics include visualization, "scraping", "writing functions", databases, Web services. You might identify the topics using the names/keywords from this "cartoon" view of statistical computing topics. Feel free to add topics and keywords.
+Computational Learning Objectives
This is different from the topic in that we want to state what we expect the student to be able to do having learned this topic. In the case of programming techniques, this may be somewhat redundant or obvious, e.g. debugging as a topic means they can debug.
Using an example from mathematical statistics, the topic covered might be Maximum Likelihood and the learning objective might be to be able to derive a maximum likelihood estimate or simply to recognize that this is an optimization problem, or to be able to use asymptotic results to compute confidence intervals.
One expectation/objective might be to expose them to the technology so they are aware of it. Another would be that they actually "master" it and can use it in another programming project
When teaching about programming and writing functions, one objective might be to have them learn the syntax of defining a function and understanding scoping rules. Another might involve them being able to reason about default arguments, partitioning a function into several helper functions that can be reused. Another might be the beginnings of software development and thinking about the ideas of object-oriented programming.
The objectives are a set of expectations. One can think of the difference between objectives and topics in the context of a course. A graduate class and an intro class might cover the same topics, but with very different objectives and expectations of what the students can do with the material.
+Prerequisite Computational Topics
Describe what computational topics the student must know to work on this activity. These will of course include the particular computational topics covered in this activity and described in the previous sections. So what we mean here is the topics not explicitly being taught in this activity, but the ones which precede these and are assumed to be known. For example, if a part of the activity is to read data from several files, the student might be expected to know how to get the list of files and about readLines() , even though these are not explicitly targeted skills being taught in this activity, but perhaps assumed to have been introduced in a previous assignment.
You might also describe how one could adapt the activity to avoid a dependency on a particular topic. For example, if the activity involves accessing a relational database but an instructor doesn't want to teach that in the course, how might she make use of the lab but replace that part. There are two aspects to this. The first is a technical matter as to how particular computations can be avoided or replaced. Of course, we can always provide functions for that particular part and hide it from the students. (But not in the case of accessing a remote database.) The second aspect relates to how it changes the pedagogical learning objectives.
+Prerequisite Statistical Background
Describe the statistical concepts and techniques the students need to know in order to understand and undertake this activity. This is related to the level of the student, but somewhat different as that also involves the amount of work we can expect. Give an indication how deep this knowledge must be and whether a heuristic explanation of the statistical idea would suffice. For example, k nearest neighbors is quite straightforward for an instructor to explain and students to get the first time they see it (with a little bit of time to digest it during the project). Clustering is similar. But linear algebra relying on linear algebra results, or material relying on an understanding of intermediate probability would be too much for an instructor to provide as background. We have been successful introducing ideas that are either algorithmic (e.g. boosting) or geometric (MDS, principal components).
+Breakdown of Computational Tasks
The idea here is that we describe to the instructor (and student) the big-picture for the entire activity by showing the high-level and abstract steps involved in the task. This is intended to be in "English" rather than code and identify the basic steps from a top-down approach. These are the sub-tasks. One can use a flow graph like the one for SPAM or Geolocation to identify the abstract/high-level/implementation-free steps involved in the analysis. We find that this is very helpful for both others reading and understanding the activity and being able to see the wood from the trees, and also in helping you think about the activity abstractly rather than in terms of code.
+Solutions
This is the meat of the writeup ( but not the template for Tuesday!). This is text and code describing one or more approaches to each task/step of the project. The majority of this is to provide the student with a model answer. We should identify where we are doing more than might be expected, i.e. "extra credit", in pursuing alternative approaches or answering additional questions.
The writeup should also include (meta-)information for the instructor. These are thoughts that you think would have helped you if you were picking this project up from somebody else and were going to use it in your class. These might include material that could also be useful for the student such as different ways to do some computation and why one approach is better. But they may also be more specific to the instructor. For example, we might provide alternative approaches if the activity is to be re-used for undergraduates, or if one is choosing to cover a topic (e.g. databases) how the problem might be approached entirely differently.
+Potential Issues and Cautionary Notes
Information about what can go wrong, e.g. approaches that take infinitely long to run, ways to read the data erroneously without raising an explicit error, subtleties in the computations. We can also discuss where students might/have become confused by the instructions or the steps involved. For example, in cross validation for k-nearest neighbor computations, the students often need help in understanding how we can calculate the distance matrix just once and then use sub-setting based on the test set and its complement to look at a sub-matrix without having to recalculate the distance matrix for the subset!
If you have given this as an assignment in your class, it is also valuable to describe common questions the students had about the activity and the programming.
+How to integrate this into different classes
Different classes will have different focii and be for different levels of students. We want you to provide suggestions and thoughts about how different instructors might use this activity within her class. This means addressing different types of courses and also different types of students. For example, we might a computational statistics class and the activity might be modified to emphasize some computational aspects. We might have computing taught without data technologies, so we might emphasize the programming aspects and hide the data acquisition parts.
Describe how this might be adapted to different levels of students by changing the tasks. In many ways, it is easy to take a rich and complex problem and simplify it by providing the students with functions for doing some of the sub-tasks. Similarly, we can give them the data as an R object (via an RDA file) rather than having them work to read it in and put it in the appropriate data structure(s).
If the problem is intended for undergraduates and is "too" simple for more advanced students, you might suggest ways to add to the project. See Extensions and Different Directions below.
+Ways to Extend the Topic
These might include alternative statistical methods that are used, This is adapting an existing computational or statistical task to do different computations, but with mostly the same inputs and outputs. For example, in the SPAM project, one might use an SVM as a different classification mechanism instead of k- Nearest Neighbors. In the birth-assassination project, we might introduce a mixture model for the death process.
+Different Directions
Suggest ways one might adapt the project to go in entirely different directions, e.g. using different technologies rather than different methods, or changing the question but using the same data. This amounts to adding different steps/branches/nodes in the task flow graph. For example, in the birth-assissanation we might introduce visualization of the tree and even animate the evolution. For the SPAM data, we might use procmail to deploy the classifier. Alternatively, we might use Perl (and the RSPerl package) to read the mail messages/mailboxes for data acquisition. For Mannheim we might provide an interactive display site to visualize the data. For cab spotting data, they might fetch "live" data themselves rather than use the archived files.
+Grading Suggestions
This provides a location where one can help instructors to identify the important elements of the students work and which are more minor. We can suggest how to grade the tasks, noting where a particular approach is "okay", but another is not. For example, when reading a data set, a student might write code that is specific to that data set and that would be legitimate. However, when a student repeats the same command with a single input changed rather than uses a looping construct (for()/apply()), that is not. We can also describe experiences we have had when using this within a class and what students often get wrong.
+Similar Activities/Projects
Here we try to identify other activities or projects that have similar pedagogical goals and activities. The intent is that we and other instructors can chose from a set of roughly equivalent and similar activities in different years for variety.
This is challenging given that we don't know about all the other projects yet. This is intended to be filled in as the similarities emerge or by those coordinating all the projects. But every suggestion of possible similarities helps, especially if there are a few sentences explaining those potential similarities, in whatever dimension they exist.